
The major design goal of the SIDS is a comprehensive and unambiguous description of the "intellectual content" of information that must be passed from code to code in a multizone Navier-Stokes analysis system. This information includes grids, flow solutions, multizone interface connectivity, boundary conditions, reference states and dimensional units or normalization associated with data.
The goal is description of the data sets typical of CFD analysis, which tend to contain a small number of extremely large data arrays. This has a number of implications for both the design of the SIDS and the ultimate physical files where the data resides. The first is that any I/O system built for CFD analysis must be designed to efficiently store and process large data arrays. This is reflected in the SIDS, which includes provisions for describing large data arrays.
The second implication is that the nature of the data sets allows for thorough description of the data with relatively little storage overhead and performance penalty. For example, the flow solution of a CFD analysis may contain several millions of quantities. Therefore, with little penalty it is possible to include information describing the flow variables stored, their location in the grid, and dimensional units or nondimensionalization associated with the data. The SIDS take advantage of this situation and includes an extensive description of the information stored in the database.
The third implication of CFD data sets is that files containing a CFD database are almost always required to be binary - ASCII storage of CFD data involves excessive storage and performance penalties. This means the files are not readable by humans and the information contained in them is not directly modifiable by text editors and such. This is reflected in the syntax of the SIDS, which tends to be verbose and thorough; whereas, directly modifiable ASCII file formats would tend to foster a more brief syntax.
It is important to note that the description of information by the SIDS is independent of physical file formats. However, it is targeted toward implementation using the ADF Core library. Some of the language components used to define the SIDS are meant to directly map into elements of an ADF node.
An early decision in the CGNS project was that any new CFD I/O standard should include a hierarchical database, such as a tree or directed graph. The SIDS describe a hierarchical database, precisely defining both the data and their hierarchical relationships.
There are two major alternatives to organizing a CFD hierarchy:
topologically based and data-type based.
In a topologically based graph, overall organization is by; information
pertaining to a particular zone, including its grid coordinates or flow
solution, hangs off the zone.
In a data-type based graph, organization is by related data.
For example, there would be two nodes at the same level, one for grid
coordinates and another for the flow solution.
Hanging off each of these nodes would be separate lists of the zones.
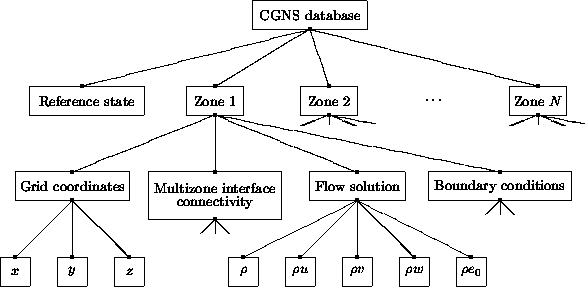
The hierarchy described in this document is topologically based; a simplified illustration of the database hierarchy is shown in the above figure. Hanging off the root "node" of the database is a node containing global reference-state information, such as freestream conditions, and a list of nodes for each zone. The figure shows the nodes that hang off the first zone; similar nodes would hang off of each zone in the database. Nodes containing the physical-coordinate data arrays (x, y and z) for the first zone are shown hanging off the "grid coordinates" node. Likewise, nodes containing the first zone's flow-solution data arrays hang off the "flow solution" node. The figure also depicts nodes containing multizone interface connectivity and boundary condition information for the first zone; subnodes hanging off each of these are not pictured.
The data structures comprising the SIDS are the result of several additional design objectives:
One objective is to minimize duplication of data within the hierarchy. Many parameters, such as the grid size of a zone, are defined in only one location. This avoids implementation problems arising from data duplication within the physical file containing the database; these problems include simultaneous update of all copies and error checking when two copies of a data quantity are found to be different. One consequence of minimizing data duplication is that information at lower levels of the hierarchy may not be completely decipherable without access to information at higher levels. For example, the grid size is defined in the zone structure, but this parameter is needed in several substructures to define the size of grid and flow-solution data arrays. Therefore, these substructures are not autonomous and deciphering information within them requires access to information contained in the zone structure itself. The SIDS must reflect this cascade of information within the database.
Another objective is elimination of nonsensical descriptions of the data. The SIDS have been carefully developed to avoid data qualifiers and other optional descriptive information that could be inconsistent. This has led to the use of specialized structures for certain CFD-related information. One example is a single-purpose structure for defining physical grid coordinates of a zone. It is possible to define the grid coordinates, flow solution and any other field quantities within a zone by a generic discrete-data structure. However, this requires the generic structure to include information defining the grid location of the data (e.g., the data is located at vertices or cell centers). Using the generic structure to describe the grid coordinates leads to a possible inconsistency. By definition the physical coordinates that define the grid are located at vertices, and including an optional qualifier that states otherwise makes no sense.
A final objective is to allow documentation inclusion throughout the database. The SIDS contain a uniform documentation mechanism for all major structures in the hierarchy. However, this document establishes no conventions for using the documentation mechanism.